A very important, and often overlooked, aspect of software development is the development environment. Given our lack of manpower, it was decided to simply adopt standard packages that will be described below: CVS, CMT, and Gaudi. An important requirement for each was support for all supported operating systems, namely Windows NT/2000, Linux, and Solaris.
We use the industry standard Concurrent Versions System (CVS) for archiving and keeping track of versions of the code. Of some importance is the way it interacts with the formal versioning system. So while it is in some sense an independent decision, it must interoperate smoothly with the code management system. For more information about CVS, please see http://www.cvshome.org.
Following a trade study, and a survey of code management systems in use by high energy physics experiments, we decided to standardize on the Code Management Tool (CMT). This represents a solution for a consistent definition of a package of software, and a way to define and manage their versions, dependence on other packages, and to generate the associated binaries. A package is a set of related components, grouped into the smallest unit of software release.
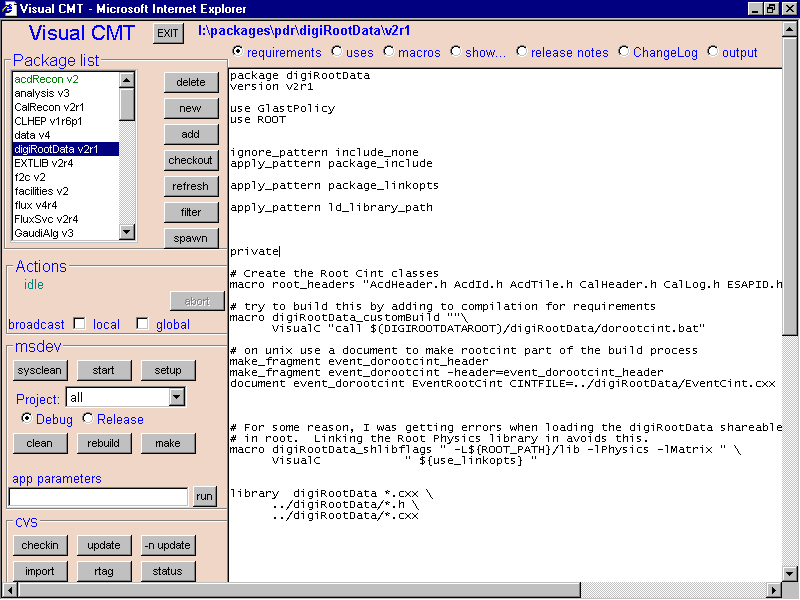
CMT provides a command line interface. While this interface provides all of the functionality necessary, a GUI interface would provide an easier mechanism for users. A prototype GUI has been developed in JavaScript. This program, called VCMT is currently in use by our Windows users. Work is underway to provide a JAVA version of VCMT that is usable on UNIX platforms as well. The following is a screen shot of the VCMT GUI:
CMT provides a seamless interface to CVS and is supported on all of our required platforms. CMT has been a considerable improvement over our previous unstructured setup, but needs tuning and coordination with the people that support the system. For more information concerning CMT, please see: http://www.lal.in2p3.fr/technique/si/SI/CMT/CMT.htm.
One of the more important recent decisions was to adopt a well-designed and documented system, Gaudi. It is an application framework designed to facilitate event-oriented analysis, with a lot of attention to allowing modular development and deployment of processing algorithms. The GLAST simulation/analysis program that was used for the proposal suffered from the lack of attention to this requirement. We learned that a system that can be managed easily by a few people may not scale to being accessible to many.
The Gaudi framework provides standard interfaces for the common components necessary for event processing and analysis. The key components of the Gaudi framework are: Algorithms, Data Objects, Converters, and Services. Converters translate data between representations, usually a persistent representation and a transient one. Services are common utilities that may be used by many algorithms. Here is a diagram of the Gaudi framework as in use by the LHCb project:

Gaudi embraces the notion that data and algorithms are separate, and provides base classes encapsulating data-like or algorithmic objects. This facilitates flexibility in that different algorithms can manipulate the same data. In the evolution from an informal system used by only a few developers to a formal, well-documented system is that data structures for Monte Carlo “truth”, raw data, and reconstructed quantities need to be clearly specified and documented. Gaudi provides a very nice model for this with the concepts of the transient data store, and converters to persistent representations of the data. The transient data store provides a shared memory mechanism allowing algorithms to share data.

The above diagram demonstrates how an algorithm interacts within the Gaudi framework, to access data. The Event Data Service provides the interface between algorithms and the transient data store. It also illustrates how a class, ConcreteAlgorithm in the above, implements interfaces, the lines connected to circles, and requests services, the lines ending in arrows.
Why Gaudi? It satisfies the requirements for flexibility, modularity, and extendibility. First it provides flexibility, in that at run time, users can determine which components are required. For example, it is trivial to replace one set of reconstruction algorithms with a different set. Gaudi uses dynamic linking extensively, thus at runtime, unused components are never loaded. The Gaudi framework provides common utilities and modularity to our simulation and analysis code. The persistency mechanism allows one to choose the persistency format at run time. Our code is thus not tied to any one particular file format.
Gaudi is supported and developed in the context of two of the major LHC experiments LHCb and ATLAS. While most of the code is not experiment-specific, clearly details of the event data definitions and geometry structures are, fortunately such code resides in separate packages. Using LHCb's code as a model, we have defined our own GLAST-specific packages for event data definitions and geometry.
Migrating to Gaudi has not come without some cost. There was a steep learning curve. The documentation, while good, has improved as we have learned more about the system. The Gaudi developers are available to exchange ideas and provide guidance when we encounter problems. Much time has been spent modifying our existing code to conform to the format that Gaudi requires. While this may sound like a heavy penalty, much of our code did not conform to our requirements for flexibility, modularity, and extendibility. A complete re-write was necessary. In fact using the Gaudi framework saved coding time, in that we used the common interfaces that Gaudi provides. We have completely migrated our simulation and reconstruction code.
For more information about the Gaudi framework, please see http://proj-gaudi.web.cern.ch/proj-gaudi/.
No software is complete without adequate documentation, both for developers and users. During the past year, we have made great strides in terms of documentation, despite our lack of manpower. Our efforts for documentation have focused on two fronts: web pages and code documentation. Ultimately, our documentation collection will be used to form our and users' and developers' guides.
The GLAST ground software home page is: http://www-glast.slac.stanford.edu/software/. A web server has been setup at SLAC, providing a central location for GLAST collaborators to create and maintain web pages. A series of web pages have been written demonstrating how to get setup to use GLAST software. Much time was devoted to detailing the specifics for both Windows and UNIX.
Web pages for each of the main software applications have
been developed. These pages are designed specifically for users with no
knowledge of the code. An example of one such page is available at:
http://www-glast.slac.stanford.edu/software/balloon/analysis/bfemApp/
To aid in code documentation, Doxygen was chosen as our documentation system. Doxygen extracts documentation direct from the source code files, generating either on-line HTML documents or an off-line reference manual. Doxygen provides an easy mechanism to keep up-to-date developers' guides. A variety of file formats are supported including PDF, Postscript, etc. For more information about Doxygen, please see http://www.stack.nl/~dimitri/doxygen/index.html.
Package-wide documentation is supported through the use of mainpage files. Each package in our CVS repository, contains a mainpage.h file. During the course of adding Doxygen comments to the code, a specific comment can be added to the package's mainpage through the use of Doxygen's \mainpage command.
While still far from perfect, our current documentation provides the first steps toward communicating the intent and usage of all of our software packages.
Coding standards help produce code with a consistent look and feel, increasing code readability. Naming conventions aid developers and users, easing name recollection. An initial list of coding standards has been developed, using the standards of other software projects as a model. Our current collection of coding standards is available at http://www.slac.stanford.edu/~jrb/glast/codeStandards.html.
While it is useful to have our coding standards documented, this does nothing to insure adherence to those standards. We are interested in providing an automated system that would check code to see if it satisfies the coding rules we have set forth. Checking would occur as code is checked into our CVS repository.
Many users of GLAST software are not interested in the details of obtaining the code, compiling the binaries and then running the applications. Instead, many people would prefer to obtain the code compiled and ready to go. In fact, most users would prefer a stable location set up for them. Additionally, a number of changes have occurred during the past year in terms of compiling and running the code - specifically the introduction of CMT/VCMT. Learning how to use these new tools can be daunting to those who would prefer to immediately run the code.
The GLAST software team has setup two stable and central sites that contain up-to-date release versions of our applications. One is the University of Washington (UW) Windows Server and the other is located on AFS space on the SLAC UNIX cluster. The UW Windows Server, as the name implies, provides applications running under Windows 2000. SLAC provides applications running on either Red Hat Linux and Solaris.